The topic of this blog post is my project at Insight Data Science, a program that helps academics, like myself (astrophysicist), transition from academia into industry. So as you have probably figured, I am looking for a job, so feel free to get in touch if you think I might be of interest to your company. The first part of the blog will be a high-level description of the data science. The specifics of the project, including code and low-level technical aspects, are treated in a second part.
During my time at Insight I consulted for a Y-combinator startup called Lynks that allows people in Egypt to ship fashion and fashion-related items from US e-commerce stores to their homes in Egypt. This is a useful service as many US e-commerce websites do not take orders from abroad. Lynks buys products from any e-retailer on behalf of customers through their 'universal shopping cart' and ships that inventory to the Lynks warehouse in Delaware, where it consolidates orders and ships completed ones to the end customer. Other than the couple of days that products pass-through Lynks warehouse, Lynks doesn't store inventory, so its theoretical product list is the combination of all US based e-commerce stores.
All the products that are ordered are currently classified by hand and Lynks has asked me to help prototype a pipeline that can assist in automating this task.
In the best case scenario this work will contribute to a fully automated classification pipeline; lower hanging fruit would be to assist the human labelers while more data is collected and the predictive models are improved.
The data currently collected for each product is an image and a short description of the item.
Here are two typical examples with the assigned labels that I am dealing with:
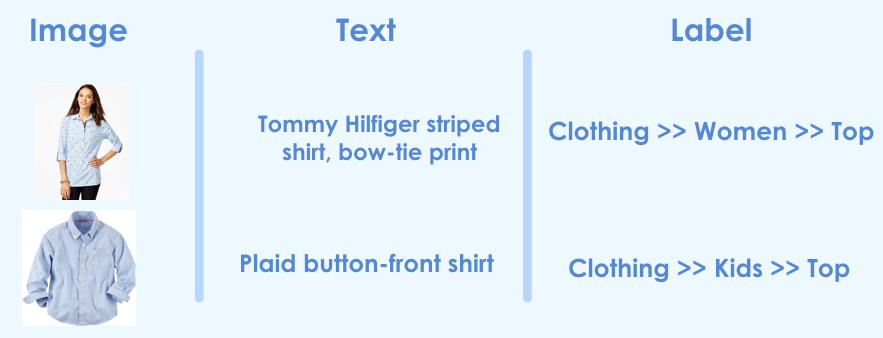
So given an image and a short description we would like to predict the label. As you can see the label is hierarchical. Given we are building a prototype I will concern myself with the flattened label. In total there are 99 unique classes and the classes are quite unbalanced, I will just work with the top 10 classes for which the classes are balanced well. The top 10 classes contain 50% of their total products.
Machine learning model¶
Images¶
My goal is to combine the text and image into a single machine learning model, since they contain complementary information. Below I explain the path I took.
For the image data, I will want to make use of a convolutional neural network, while for the text data I will use NLP processing before using it in a machine learning model.
Although our data set is not small (~5000 in the training set) it can hardly be compared to Image-Net data set containing 1.2 million images in a 1000 classes.
For this reason it make sense to leverage the power of pre-trained network that has been been trained on Image-Net which already has the capability of extracting useful features for natural images. Leveraging a pre-trained machine learning model is called transfer learning. On the text side of the feature space a simple bag of words model will be sufficient given that the mere presence of a word is very informative and I don't expect a gain from interactions.
So I created a neural network that has a convolutional branch one on side while the other branch accepts the vectorized words. I settled on the following architecture for the model:
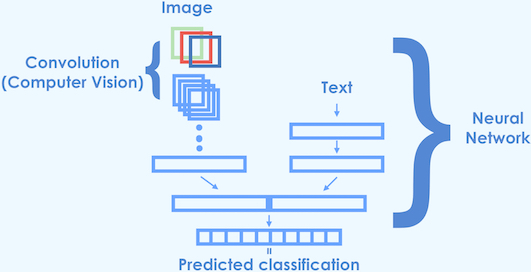
For this work I used the Keras library for which a pre-trained VGG-16 network is available. I won't go in detail on how to do the transfer learning as the author of Keras has written a very comprehesive guide to transfer learning.
Text¶
The information content of the text varies quite widely. In some cases, the item can be classified accurately using the text alone (e.g., 'men's shirt'); in other, rarer cases the text will not be as informative (e.g., 'bronx 84 graphic t'). Furthermore, the text in previous example might be difficult to classify as male or female since the text does not contain any gender information. Having said that, we have to keep in mind what the potential purposes of this classification process are. If, for example, classification is used to estimate the shipping cost of the product, a misclassification between a male and female shirt won't be of monetary importance; however, if it is used to understand the clientele in a better way this mistake is very relevant.
Performance¶
Above I explained that I would like to use a neural network architecture that combines both images and text. This is quite a cannon to wield and we should check how far we can get with just text. Below is the performance of using the text alone, the images and the combination of both.
| Images | Text | Images + Text |
|---|---|---|
| 85% | 86% | 93% |
For the text I have tried random forest and logistic regression both for which I it was easy to do hyperparameter optimization using random search, logistic regression with L2 regularization seems to have the edge over L1 regularization while none of random forest models were competitive.
The text only analyis is slighly better than the image only analyis while at the same time being a lot cheaper.
But is it clear that the combination of both the images and the text leads to a large increased performance.
There a few more things we can try to optmize even further. One such trick is hyperparameter optimization, like I did with the text only model. Given that feedback loop for hyperparameter optimization is slow due to the fact that training a deep learning model takes quite a bit of time, I opted to use this only as a last measure.
A more natural way forward is to attempt to find convolutional filters that are better suited given the task at hand.
The pretrained network VGG than I’m using was trained on Image-Net which has 1000 classes, none of which to my knowledge are clothing or fashion items, so it makes sense to try and adjust the convolutional layers that have learned to identify higher-level features of the training set. This process is called fine tuning. I opted for fine-tuning the last 3 convolutional layers, here are the results.
| Images | Text | Images + Text | Images + Text + Fine Tuning |
|---|---|---|---|
| 85% | 86% | 93% | 94% |
The fine tuning brought another 1% in accuracy, making the deep learning model clearly the best model with 94% accuracy. The errors on these classification metrics are of the order 0.01% so all the differences here are significant.
Technical aspects¶
In this part I will cover some of the technical parts of the project, along with some code snippets that might be of interest to the reader. I first defined the VGG architecture and loaded in the weights; this process is also covered in a blog post by the Keras author François Chollet. The following code cell defines two functions: one defines the convolutional part of the VGG architecture and sets the layers so they cannot be trained as we want to use transfer learning, and the other loads the weights.
def get_base_model():
"""
Returns the convolutional part of VGG net as a keras model
All layers have trainable set to False
"""
img_width, img_height = 224, 224
# build the VGG16 network
model = Sequential()
model.add(ZeroPadding2D((1, 1), input_shape=(3, img_width, img_height), name='image_input'))
model.add(Convolution2D(64, 3, 3, activation='relu', name='conv1_1'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(64, 3, 3, activation='relu', name='conv1_2'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(128, 3, 3, activation='relu', name='conv2_1'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(128, 3, 3, activation='relu', name='conv2_2'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(256, 3, 3, activation='relu', name='conv3_1'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(256, 3, 3, activation='relu', name='conv3_2'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(256, 3, 3, activation='relu', name='conv3_3'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu', name='conv4_1'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu', name='conv4_2'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu', name='conv4_3'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu', name='conv5_1'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu', name='conv5_2'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu', name='conv5_3'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
# set trainable to false in all layers
for layer in model.layers:
if hasattr(layer, 'trainable'):
layer.trainable = False
return model
def load_weights_in_base_model(model):
"""
The function takes the VGG convolutian part and loads
the weights from the pre-trained model and then returns the model
"""
weight_file = ''.join((WEIGHTS_PATH, 'vgg16_weights.h5'))
f = h5py.File(weight_file)
for k in range(f.attrs['nb_layers']):
if k >= len(model.layers):
# we don't look at the last (fully-connected) layers in the savefile
break
g = f['layer_{}'.format(k)]
weights = [g['param_{}'.format(p)] for p in range(g.attrs['nb_params'])]
model.layers[k].set_weights(weights)
f.close()
return model
Now we want to expand the model so that it can accept the vectorized text as well as the images. To make the code adaptable, we will have to pass in several variables such as the number of classes and the size of the vectorized text.
def make_final_model(model, vec_size, n_classes, do=0.5, l2_strength=1e-5):
"""
model : The VGG conv only part with loaded weights
vec_size : The size of the vectorized text vector coming from the bag of words
n_classes : How many classes are you trying to classify ?
do : 0.5 Dropout probability
l2_strenght : The L2 regularization strength
output : The full model that takes images of size (224, 224) and an additional vector
of size vec_size as input
"""
### top_aux_model takes the vectorized text as input
top_aux_model = Sequential()
top_aux_model.add(Dense(vec_size, input_shape=(vec_size,), name='aux_input'))
### top_model takes output from VGG conv and then adds 2 hidden layers
top_model = Sequential()
top_model.add(Flatten(input_shape=model.output_shape[1:], name='top_flatter'))
top_model.add(Dense(256, activation='relu', name='top_relu', W_regularizer=l2(l2_strength)))
top_model.add(Dropout(do))
top_model.add(Dense(256, activation='sigmoid', name='top_sigmoid', W_regularizer=l2(l2_strength)))
### this is than added to the VGG conv-model
model.add(top_model)
### here we merge 'model' that creates features from images with 'top_aux_model'
### that are the bag of words features extracted from the text.
merged = Merge([model, top_aux_model], mode='concat')
### final_model takes the combined feature vectors and add a sofmax classifier to it
final_model = Sequential()
final_model.add(merged)
final_model.add(Dropout(do))
final_model.add(Dense(n_classes, activation='softmax'))
return final_model
The above code blocks allow us to define a model that takes images and an additional vector (e.g., text) and puts it all in neural network that can be trained. In this model we simply concatenate the feature vectors extracted from the text and apply a softmax classification layer to the concatenated vector. I tried more complex models, but all had worse performance.
Having defined the model, we would like to train and validate it, preferably with the processing tools that the Keras library provides. To make this possible we will have to adapt the Keras library pre-processing methods, since they only work for images. After first building my own (not so pretty) processing pipeline, I opted for the more elegant and robust solution of adapting the existing Keras capabilities. I went with adapting the 'flow_from_directory' method. The original method expects that all the images belonging to the same class live in the same sub-folder. This can be easily extended so that method not just looks for an image in the folder but also an numpy binary (.npy) file. This file is expected to have same name as the image file just with the '.npy' extension. So if the image is named 54567.jpg the pipeline expect there to be a 54567.npy file in the same folder. The fork of Keras with this feature implemented can be found here.
So what about classes that are not in the training sample¶
A relevant question in any machine learning model and one that is very relevant for this project is: what happens when the model is fed and image with accompanying text that does not belong to any of the classes in the training set? From the mechanics of a neural network we know that the softmax classifier will (incorrectly) classify an out-of-train-class object as belonging to one of the 10 classes. An example here could be an image of an e-commerce product like a book with the accompanying description.
In this case, the fact that we have the bag-of-words vector makes this problem tractable. Recall that the bag-of-words model will return the word count for all unique words that are in the training set. For the case of the book, it is likely that not even a single word in the book description was seen in the training set. Therefore, every entry of the text vector will be zero. If such a vector is encountered it can be considered out-of-training sample and hence sent to a human classifier. A more challenging problem is when we only have image data as input. I hope to write about addressing that problem in future blog posts.